HTTP/2 协议
HTTP/1.1 与 HTTP/2 相隔了大概20年,但是从目前的研究和实验情况来看,我们不可能等上几十年才升级到下一个版本,h2 在逐渐的普及。 h2 和 h1 的最大差别在于在 http 层上增加了分帧层;把原来的 http 层的数据拆分成多种帧类型,并在每种类型前加上协议性的帧首部。基于二进制分帧的优点:
- 传输使用的编码方式改变(采用帧、流模式),不用创建多个 TCP 连接,单个连接就可以有多个流(处理主页面和所有子元素的请求),能够减少延迟,服务器和浏览器的 socket 负载也大大减少。
- 并行处理,乱序发送帧,不再采用 pipeline 阻塞方式
- 传输的功能得以扩展(如服务端推送、首部压缩、优先级、流量控制)。
学习 HTTP/2 最好的文档是 RFC 7540。
1 连接
HTTP/2 对每一个域名只会开启一个连接(本质上就是 一个 TCP/Socket),HTTP/2 的设计思路是尽量在单个 TCP/IP socket 上通信。
1.1 启用 http/2
对于浏览器来说,它无法知晓该服务端是否支持了 h2,有三种方式来了解是否支持。
- 为"http" URIs启用HTTP/2协议:客户端利用 Upgrade 首部来表明期望使用 h2;服务端返回
101 Swiching Protocols; - 为"https" URIs启用HTTP/2协议:客户端在 ClientHello 中设置应用层协议协商(Application-Layer Protocol Negotiation,ALPN)扩展来表明期望使用 h2;服务端在 ServerHello 中同样返回,所以 h2 在创建 TLS 握手的过程中完成协商,不需要多余的网络通信。
- 先知情况下启用HTTP/2:使用 HTTP Alternative Services 或 Alt-Svc。
1.2 http/2 连接前奏
支持了之后还要再确认使用 h2,两端都需要发送前奏,作为对所使用协议的最终确认,并确定HTTP/2连接的初始设置。客户端和服务端各自发送不同的连接前奏。
- 客户端连接前奏以一个24字节的序列开始,用十六进制表示为:
0x505249202a20485454502f322e300d0a0d0a534d0d0a0d0a即,连接前奏以字符串"PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n"开始,一般称 Magic,注意它不是帧。这个序列后面必须跟一个可以为空的 SETTINGS 帧 - 服务端连接前奏包含一个可能为空的 SETTINGS 帧( 6.5节 ),它必须由服务端在HTTP/2连接中首先发送。
- 在发送完本端的连接前奏之后,必须对收到的作为对端连接前奏一部分的 SETTINGS 帧进行确认(ACK)。
1.3 SETTINGS 帧
SETTINGS 帧只能应用到整个连接,不能应用于单个流,即 SETTINGS 帧的 stream identifier 必须为 0x0;
SETTINGS 帧包含了若干有序的键值对,每个键值对的格式如下:
+-------------------------------+
| Identifier (16) |
+-------------------------------+-------------------------------+
| Value (32) |
+---------------------------------------------------------------+
SETTINGS 帧的标识符跟其它的不一样,只有 ACK 一个标识,取值 0x0 和 0x1,前者表示设置请求,后者表示确认响应;设置请求发送的 SETTINGS 帧包含了若干有序的键值对,确认响应没有负载数据。
Identifier 参数列表:
| 名称 | 默认值(octets) | 描述 | |
|---|---|---|---|
| SETTINGS_HEADER_TABLE_SIZE (0x1) | 4096 | 重新指定 HPACK 所用的首部表的最大尺寸 | |
| SETTINGS_ENABLE_PUSH (0x2) | 1 | 如果设置为 0,当前端不会发送 PUSH_PROMISE | |
| SETTINGS_MAX_CONCURRENT_STREAMS (0x3) | 无限制 | 表明发送端能够并行接收的流的最大数量 | |
| SETTINGS_INITIAL_WINDOW_SIZE (0x4) | 65535(64KB) | 表明发送端流量控制的初始窗口尺寸 | |
| SETTINGS_MAX_FRAME_SIZE (0x5) | 16384(16MB) | 发送端希望接收的最大帧尺寸;这个值必须介于初始值和 2^24-1(16MB) 之间 | |
| SETTINGS_MAX_HEADER_LIST_SIZE (0x6) | 无限制 | 该设置告诉通信的另一端,本端期望接收的最大首部的尺寸 |
1.4 PING 帧
PING 帧用以计算两端之间的往返时间 RTT,只有一个标识位 ACK,这个标识位和 SETTINGS 帧一样意识。
1.5 关闭连接
GOAWAY 帧用于礼貌地关闭连接。这个是连接层的帧,也就是发送时流 ID 要设置为 0x0,
2 帧
HTTP/2 是基于帧(frame)的协议,帧是 HTTP/2 最小传输单位;采用分帧是为了将重要的信息都封装起来,让协议的解析方轻松解析。基于帧的协议,所有的帧都固定用 9 个字节的帧首部加上帧负载数据组成。
+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+-------------------------------+
|R| Stream Identifier (31) |
+=+=============================================================+
| Frame Payload (0...) ...
+---------------------------------------------------------------+
- 帧首部字段解析:
| 名称 | 长度 | 描述 |
|---|---|---|
| Length | 3字节 | 帧负载长度,2^14(16KB)是默认的最大帧长度,如果需要更大的帧,必须在 SETTINGS 帧设置 |
| Type | 1字节 | 当前帧类型 |
| Flags | 1字节 | 具体帧类型的标识,影响负载的协议结构 |
| R | 1位 | 保留位 |
| Stream Identifier | 31位 | 每个流的唯一 ID |
| Frame Payload | 长度可变 | 真实的帧内容,长度为 Length |
- 帧类型:
| 名称 | ID | 描述 |
|---|---|---|
| DATA | 0x0 | 传输流的核心内容 |
| HEADERS | 0x1 | 包含 HTTP 首部,和可选的优先级参数 |
| PRIORITY | 0x2 | 指示或者更改流的优先级和依赖 |
| RST_STREAM | 0x3 | 允许一端停止流 |
| SETTINGS | 0x4 | 协商连接级参数 |
| PUSH_PROMISE | 0x5 | 提示客户端,服务端要推送些东西 |
| PING | 0x6 | 测试连接可用性和往返时延(RTT) |
| GOAWAY | 0x7 | 告诉另一端,当前端已结束 |
| WINDOW_UPDATE | 0x8 | 协商一端将要接收多少字节(用于流量控制) |
| CONTINUATION | 0x9 | 用以扩展 HEADERS 数据块 |
3 流
流(stream)的定义是:HTTP/2连接上独立、双向的帧序列交接。流代 ID 表示一次 HTTP 请求和响应所产生的一系列帧,流 ID 用来标识帧所属的流;单个 socket 上可以创建多个流,HTTP/2 的设计思路是尽量在单个 TCP/IP socket 上通信。 流 ID 在设计时就避免了客户端和服务端之间的流 ID 冲突,也可以轻地判断流的源头。
- 客户端会从 1 开始设置流 ID,之后每新开启一个流,就会增加 2,并一直使用奇数。
- 服务端开启在 PUSH_PROMISE 中标明的流时,设置的流 ID 从 2 开始,之后一直使用偶数。
- 0 是保留数字,用于连接级控制消息,不能用于创建新的流。
帧在流上发送的顺序非常重要,最后接收方会把相同 Stream Identifier (同一个流) 的帧重新组装成完整消息报文
3.1 消息
帧消息的关注点在于 HEADERS 和 DATA 这两个帧类型,这也是由 h1 的头部和数据拆分而来。 帧首部必须以 +END_STREAM、+END_HEADERS 结束。
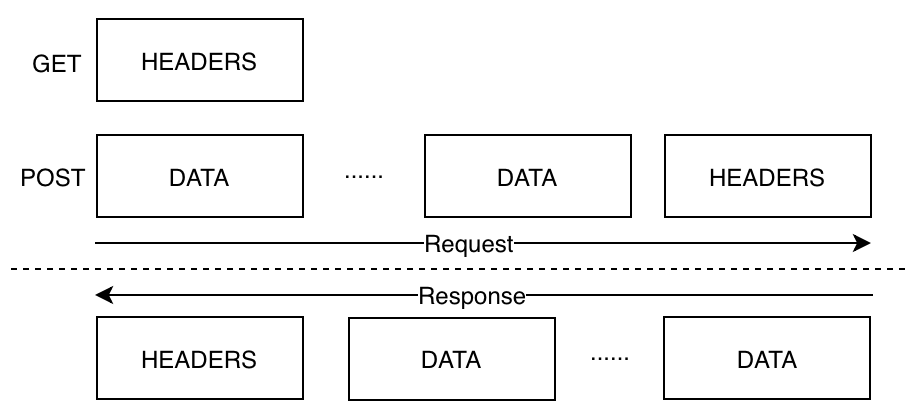
h1 把 header 拆分成两部分:请求/状态行(GET / HTTP/1.1、HTTP/1.1 200 OK)、首部(Host、User-agent等);而 h2 取消了这种拆分,一切都是 header,并引入了伪首部(Pseudo-Header): (1)请求伪首部::method、:scheme、:authority、:path (2)响应伪首部::status
- HEADERS 帧
+---------------+
|Pad Length? (8)|
+-+-------------+-----------------------------------------------+
|E| Stream Dependency? (31) |
+-+-------------+-----------------------------------------------+
| Weight? (8) |
+-+-------------+-----------------------------------------------+
| Header Block Fragment (*) ...
+---------------------------------------------------------------+
| Padding (*) ...
+---------------------------------------------------------------+
帧字段的部分解析可以看 PRIORITY 帧。
标识位(Flags):
| 名称 | 位 | 描述 |
|---|---|---|
| END_STREAM | 0x1 | 表明这是流中最后的帧(流终止) |
| END_HEADERS | 0x4 | 表明这是流中最后一个 HEADERS 帧;如果此标识未设置,表示随后会有 CONTINUATION 帧 |
| PADDED | 0x8 | 表明此帧添加了填充数据,要使用 Pad Length 和 Padding 字段 |
| END_STREAM | 0x20 | 设置了此标识,表明要使用 E、Stream Dependency 以及 Weight 字段 |
- DATA 帧
+---------------+
|Pad Length? (8)|
+---------------+-----------------------------------------------+
| Data (*) ...
+---------------------------------------------------------------+
| Padding (*) ...
+---------------------------------------------------------------+
标识位(Flags):
| 名称 | 位 | 描述 |
|---|---|---|
| END_STREAM | 0x1 | 表明这是流中最后的帧(流终止) |
| PADDED | 0x8 | 表明此帧添加了填充数据,要使用 Pad Length 和 Padding 字段 |
3.3 流量控制
WINDOW_UPDATE 帧流量控制可以应用到单个流,也可以应用到连接承载的所有流(流 ID 为 0x0),这点与 SETTINGS 不一样。需要注意的是,在单个流上指定的 WINDOW_UPDATE 帧也会作用于连接层的流量控制。 在流建立的时候,窗口大小默认都是 2^16-1(64KB);流量控制不能关闭,把窗口最大值设定为 2^31-1(2GB) 就等效于禁用它;
+-+-------------------------------------------------------------+
|R| Window Size Increment (31) |
+-+-------------------------------------------------------------+
该帧没有标识符(Flags)。
3.4 优先级
客户端拿到页面分析依赖关系的时候是通过声明依赖关系树和树里的相对权重实现的。
index.html
- style.css
- critical.js
- less_critical.js(weight 20)
- photo.jpg(weight 8)
- header.jpg(weight 8)
- ad.js(weight 4)
依赖树是客户端自己维护的,而权重则需要告诉服务端实现对象优先传输顺序,不过说到底,做什么以及如何处理优先级,最终还是得听服务器的,服务器仍有做它自己认为正确的事的权力。 那么客户端怎么告诉服务端的?通过 HEADERS 帧和 PRIORITY 帧,客户端可以明确的和服务沟通它需要什么,以及它需要这些资源的顺序。 PRIORITY 帧可以看成是 HEADERS 的子部分:
+-+-------------------------------------------------------------+
|E| Stream Dependency (31) |
+-+-------------+-----------------------------------------------+
| Weight (8) |
+-+-------------+
帧字段:
- E 标识当前的流是否为专用,是否不依赖其他流
- Stream Dependency 流依赖,如果当前流依赖其他流,标识其所依赖的流
- Weight 当前流的相对权重
该帧没有标识符(Flags)。
3.5 CONTINUATON 帧
有些帧的帧负载很简单,比如 DATA,只有 Pad Length 后面就是 DATA;有些帧负载配置较多,即当 HEADERS、PUSH_PROMISE 帧首部块片段(header Block Fragment)较大(少见),需要分帧传输,有两种选择: (1)再次使用 HEADERS、PUSH_PROMISE 等帧,缺点是帧负载的配置重复传递,还得处理帧负载的配置有分歧的情况,可能引起麻烦。 (2)采用新的 CONTINUATON 帧,没有帧负载的配置,仅仅有 header Block Fragment,缺点是 CONTINUATON 和前面的帧必须是有序的,会减损多路复用的益处。
最终协议开发者选择了处理较为简洁的新帧。
+---------------------------------------------------------------+
| Header Block Fragment (*) ...
+---------------------------------------------------------------+
标识位(Flags):
| 名称 | 位 | 描述 |
|---|---|---|
| END_HEADERS | 0x4 | 表明这是流中最后一个 HEADERS 帧;如果此标识未设置,表示随后会有 CONTINUATION 帧 |
3.6 关闭流
如果要终止一个流,可以将 RST_STREAM 加在该流的两端。帧字段只有 32 位的 Error Code。
4 推送响应
PUSH_PROMISE 帧可以看成是服务端响应的首部,字段如下:
+---------------+
|Pad Length? (8)|
+-+-------------+-----------------------------------------------+
|R| Promised Stream ID (31) |
+-+-----------------------------+-------------------------------+
| Header Block Fragment (*) ...
+---------------------------------------------------------------+
| Padding (*) ...
+---------------------------------------------------------------+
有几个属性需要理解:
- Promised Stream ID 推送响应一定会对应到客户端已发送的某个请求;
- PUSH_PROMISE 和 HEADERS 帧字段是很相似的,比如 Promised Stream ID 和 Stream Dependency 是一样的意思,只是所处的角度不同所以描述不同;
- :method 首部的值必须确保安全。安全的方法就是”幂等“的那些方法;
- 会创建新的偶数的流 ID;
- 被发送的对象必须确保是可缓存的;
- 应该早于客户端接收到可能承载着推送对象的 DATA 帧推送,比如客户端请求 HTML,那么服务器应早于完整推送 HTML 前推送 PUSH_PROMISE。不过 h2 足够健壮,可以优雅地解决这类问题,但确实是浪费流量了。
客户端可以拒收,使用 RST_STREAM 帧。另外还有 PROTOCAL_ERROR 当 PUSH_PROMISE 涉及的协议不安全,或者客户端已经在 SETTINGS 帧中表明自己不接受推送时,仍然进行推送。不过在双方都了解对方想法前可能无法避免地推送大量资源。
如果服务器接收到一个页面的请求,它需要决定是推送页面上的资源还是等客户端来请求。决定的过程需要考虑到如下方面:
- 资源已经在浏览器缓存中的概率;
- 从客户端来看这些资源的优先级;
- 可用的带宽,以及其他类似的会影响客户端接收推送的资源;
如果服务器选择正解,那就真的有助于提升页面的整体性能,反之则会损耗页面性能,这也是如今通用服务端推送解决方案非常少的原因。估计在 APP 上应用场景较多。
5 首部压缩
HPACK 的知识点相对比较多,最好的方式是通读文档 RFC 7541,以下只是做一些归纳。 HPACK 没有定义可扩展性机制,比如 Integer Representation、静态表 等都是无法扩展的;只能通过定义完全的替代品来更改格式。估计这个是 HTTP/2 直接升级到 HTTP/3 的原因吧。
5.1 学习的基础
5.1.1 术语
这 4 个术语是一定要理解的,才能读懂文档:
- Header Field:一个键值对;未编码;
- Header List:多个 Header Field 有序连接起来,未编码;
- Header Field Representation:单个 Header Field 的表示方法(即用 HPACK 压缩算法编码),解码后就是 Header Field;
- Header Block:多个 header field representations 有序连接起来,解码后就是 Header List;
也就是说 HTTP/2 的首部有序列表编码后就是 Header Block,解码后就是 Header List。且 Header List 中的顺序要和 Header Block 中的顺序一致。
比如:(数字是16进制)
:method: GET HPACK 编码后是 82;
:authority: localhost HPACK 编码后是 41 86 a0 e4 1d 13 9d 09;
单个表示方法:(括号表示这个键后面的值的字节数)
:method(3)GET 就是 Header Field, 82 就是 Header Field Representation;
多个连接起来:
:method(3)GET:authority(9)localhost 就是 Header List,82 41 86 a0 e4 1d 13 9d 09 就是 Header Block;
除了术语,我们还要学习一下原始数据类型的表示和静态Huffman码。
5.1.1 原始数据类型的表示
这部分很重要,一定要理解透,Primitive Type Representations 原始数据类型的表示:
- Integer Representation:表示对索引值(静态表或动态表索引条目)引用的表示法。
这部分可以看伪代码,N 可以灵活设置,后面的 Header Field Representation 使用了 N 等于
(1)7、(01)6、(001)5、(0000)4、(0001)4这 5 种情况(前面括号是 octet(8位) 的二进制前缀)。要理解这段代码一定要看原文档,我就不引用了。
if I < 2^N - 1, encode I on N bits
else
encode (2^N - 1) on N bits
I = I - (2^N - 1)
while I >= 128
encode (I % 128 + 128) on 8 bits
I = I / 128
encode I on 8 bits
- String Literal Representation:表示字符串字面量表示法,可以是直接地编码(ASCII),或使用静态Huffman码
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| H | String Length (7+) |
+---+---------------------------+
| String Data (Length octets) |
+-------------------------------+
其中 H 为 1 表示采用静态Huffman码,为 0 表示采用直接地编码。
5.1.2 静态Huffman码
静态Huffman码本质上是一个查表的编码(静态Huffman码表)(其实 ASCII 也是一个查表编码)。原理就是一个对字符使用概率的重新编码,常规一个字符是用8位表示,但 Huffman 常用的字符采用5位、6位等表示。大概估算一般能够缩短1/3的长度(比如 9 个字符常规是 9*8 = 72 位表示,采用 Huffman 后最少可以只用 9*5 = 45 位表示,尾部填充后最少是 6 个字符的长度,少了 3 个字符)。
5.2 索引表
<---------- Index Address Space ---------->
<-- Static Table --> <-- Dynamic Table -->
+---+-----------+---+ +---+-----------+---+
| 1 | ... | s | |s+1| ... |s+k|
+---+-----------+---+ +---+-----------+---+
⍋ |
| ⍒
Insertion Point Dropping Point
请求端和响应端各维护了两张索引表:静态表和动态表。其中静态表的条数是固定的 s = 61,在所有的编码或解码上下文间共享的一套数据;动态表编号从 62 开始,每个动态表只针对一个连接,每个连接的压缩解压缩的上下文有且仅有一个动态表。
5.3 编码解码
要理解这部分一定要理解透 5.1.1 节和 5.1.2 节。
首部压缩最重要的就是实现 Header Field Representation(编码的头部字段)。一个编码的头部字段可由一个索引或一个字面量表示。解码就是反向过程。
5.3.1 Indexed Representation 索引表示
索引的表示法将头部字段定义为对静态表或动态表中条目的引用, 这里就是使用了 N = (1)7 实现的。
5.3.2 Literal Representation 字面量表示
字面量的表示通过描述头部字段的名称和值来定义头部字段。头部字段的名称可被字面地表示,或表示为对静态表或动态表中条目的引用。头部字段的值由字面量表示。
定义了三种不同的字面的表示,每一种都分 Indexed Name 和 New Name 两种情况,表示头部字段的名称是否为对静态表或动态表中条目的引用,所以合起来算是六种:
- 将头部字段作为新条目添加到动态表的起始位置的字面地表示,Literal Header Field with Incremental Indexing;这里就是使用了 N = (01)6 实现的。
- 不向动态表添加头部字段的字面量表示,Literal Header Field without Indexing;这里就是使用了 N = (0000)4 实现的。
- 不向动态表添加头部字段的字面量表示,且这个头部字段总是使用字面的表示,Literal Header Field Never Indexed;这里就是使用了 N = (0001)4 实现的。
可按照 安全注意事项 的指导来选择这三种字面的表示中的一个,以保护敏感的头部字段值。
头部字段的名字或值的字面表示的字节序列可以是直接地编码,或使用静态Huffman码。静态Huffman码可以看 5.1.2 节.
上面三种不同的字面的表示中,只有第一种需要管理动态表(条目插入、条目被逐出)。
5.3.3 Dynamic Table Size Update 动态表大小更新
这里就是使用了 N = (001)5 实现的。
5.4 简单例子
- :method: GET => 82, 采用 N = (1)7 索引表示表,Representation: Indexed Header Field;采用了查静态表的方式实现,即 10000010(0x82)。
- :authority: www.jemper.cn => 41 8a f1 e3 c2 fd 0b 4d 65 b1 72 55, 采用 N = (01)6,Representation: Literal Header Field with Incremental Indexing - Indexed Name,看一下 RFC 文档即可找到该表示法:
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| 0 | 1 | Index (6+) |
+---+---+-----------------------+
| H | Value Length (7+) |
+---+---------------------------+
| Value String (Length octets) |
+-------------------------------+
(1)第一个 octets: :authority 这部分通过查静态表 Index = 1,首两位是01,所以是 01000001(41);
(2)第二个 octets: 第一个 bit 位表示是否是 Huffman 编码,这里当然要用 Huffman 编码,所以是 1,后面一共用 10 octets 长度表示值,所以是 10001010(8a);
(3)第三个 octets 到结束:www.jemper.cn 这个值的每一个字节通过查 Huffman 表得知分别为:1111000 1111000 1111000 010111 1110100 00101 101001 101011 00101 101100 010111 00100 101010;一共是 79 bit,后面用 1 填充到 octets 的倍数,即用 10 octets 能完全表示,连接起来就得到要传输的值:11110001 11100011 11000010 11111101 00001011 01001101 01100101 10110001 01110010 01010101(f1 e3 c2 fd 0b 4d 65 b1 72 55)。
粗糙的结论::method: GET 11 个字节只用了 1 个字节传输, :authority: www.jemper.cn 24 个字节只用了 12 个字节;即 35 个字节只用了 13 个字节传输,压缩率达 62.8%;其中静态表贡献了 94.7%,Huffman 贡献了 23%,可见一斑。
有趣轶事:
- 魔法字节流的 PRI 其实就是美国国家安全局 PRISM(棱镜)监控计划的一个笑话。
- 由早期的 HTTP/2.0 改成 HTTP/2 表示不能保证语义向后兼容,也就是不会有 2.1、2.2 之类的版本。
参考文献 [1] HTTP/2 RFC7540. https://httpwg.org/specs/rfc7540 [2] HPACK RFC7541. https://httpwg.org/specs/rfc7541 [3] HPACK RFC7541 中文文档. https://www.wolfcstech.com/2016/10/29/hpack-spec/ [4] Stephen Ludin, Javier Garza. HTTP/2 基础教程. 版次:2018年1月第1版 [5] 谈谈 HTTP/2 的协议协商机制. https://imququ.com/post/protocol-negotiation-in-http2.html. Apr 14, 2016 [6] HTTP2 详解. https://blog.wangriyu.wang/2018/05-HTTP2.html 2018.08.31 [7] 掌握 HTTP2.0 http://jartto.wang/2018/03/30/grasp-http2-0/