汇编语言
图灵在数理逻辑方面的理论研究,间接地创造了机器指令设计的基本方法,计算机界最高奖项也因此称图灵奖;现代计算机之父冯诺依曼,于1945年提出了“存储程序通用电子计算方案”,提出了指令数据存储思想,并在 1951 年成功研制出了冯诺依曼结构的 IAS 计算机(现在计算机的原型机),奠定了现代计算机的微体系设计和程序结构设计。
1 基础知识
1.1 冯诺依曼的“存储程序”思想
任何要计算完成的工作都要先被编写成程序,然后将程序和原始数据送入主存并启动。一旦程序被启动,计算机应能在不需操作的人员干预下,自己完成逐条取出指令和执行指令的任务。
1.2 计算机系统抽象层
计算机就是一层层的抽象设计,比如 ISA 指令集体系结构是对硬件的抽象,机器语言、汇编语言、高级语言都是通过 ISA 使用硬件的。计算机专业课程基本上是围绕其中一个或多个抽象层开展教学,但从业人员要知道你所工作的层处在整个层次的哪一部分,跟哪些相关,要有整个的背景知识。
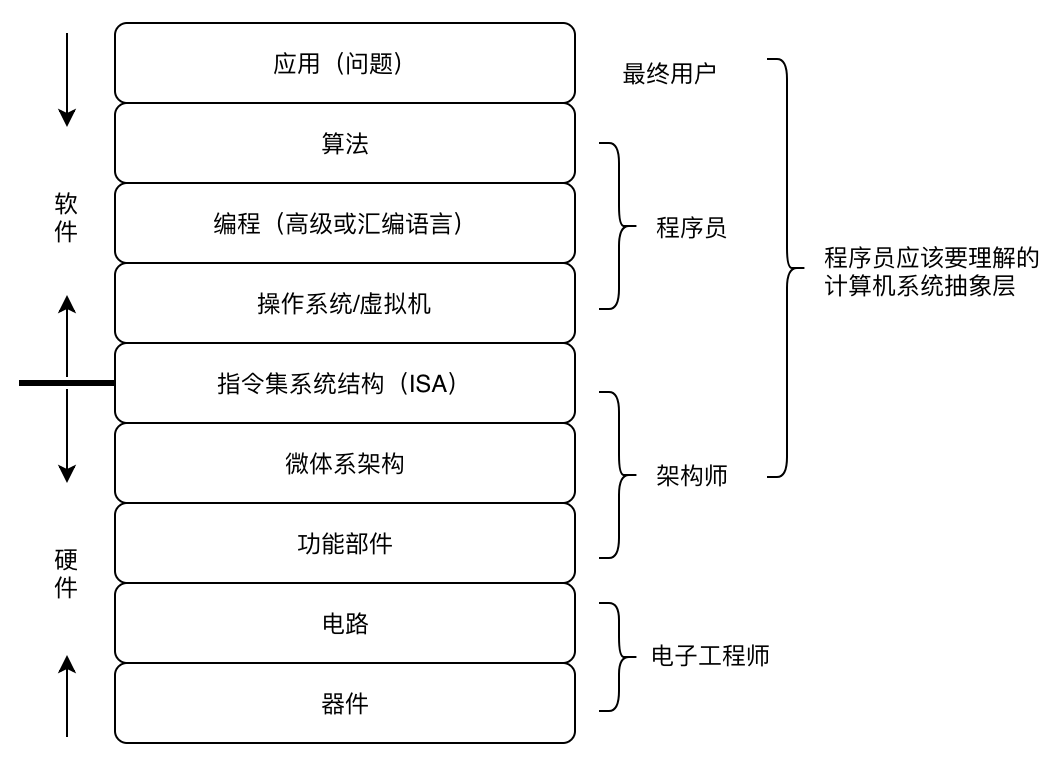
对程序员来说,硬件部分要理解微体系架构的实现方式,这部分我们放在第二部分讲;软件部分大致可以分为语言处理系统和操作系统这两大系统。
1.3 语言处理系统
语言处理系统由“语言处理程序”和“语言运行时系统”组成:
- 语言处理程序:高级语言源程序 –编译-> 汇编文本 –汇编-> 目标二进制 –链接-> 目标二进制。一般来说,编译有广义的编译(高级语言源代码转成机器语言);也有狭义的编译(高级语言源代码转成汇编文本),这需要根据上下文理解就可以了,一般情况都是指狭义的编译。除了编译方式之外,还有解释方式运行的解释程序(如 PHP)。 要理解编译器、汇编器和链接器都是具有相应功能的软件,比如汇编器是将汇编语言翻译成硬件理解的二进制执行文件的软件。
- 语言运行时系统:GC、协程调度、优化、库函数、初始化等。
1.4 操作系统
汇编语言及以上层都通过操作系统抽象层使用指令集,操作系统主要由“人机接口”和“操作系统内核”组成:
- 人机接口:界面操作,GUI 操作和 CUI 操作
- 操作系统内核:输入输出等系统调用、虚拟内存和物理内存分配,进程和内核线程调度,多任务多用户等。
1.5 什么叫自举
初学者可能会误认为是鸡和蛋的问题,要理解自举,就是清楚编译器本身就是一个程序,它的功能就是把源代码翻译为计算机可执行的程序,它和被翻译的语言并没有关系。下面以 Go 语言作为例子:
- Go 语言:发明了 Go 语言,Go 源代码由 Go 程序和 Go 汇编(plan9 语法)组成;
- C 写的编译器程序:前期得用 C 语言写一个 Go 源程序的编译器,用来把 Go 源代码编译成汇编文本;
- Go 写的编译器程序:用 Go 写一个把 Go 源代码编译成汇编文本的程序,并用“步骤 2”生成的 C 编译器编译成可执行程序;
- 用 “Go 写的编译器程序” 去编译 “Go 源代码”,不再用“步骤 2”生成的 C 编译器去编译。
其中第 3 步就是实现了自举,因为编译器既是一个复杂的工程,也有一套成熟的评价体系,一般能实现自举的程序可以说是完备成熟的编程语言了。
1.6 既简单又复杂的汇编
简单是因为汇编语言采用助记符来编写程序。复杂是因为汇编并不指代单一语言,相反,一种特定的汇编语言使用来自单一处理器指令集和操作数。因此,存在着多种汇编语言,每种都对应一类处理器。程序员可能会讨论 MIPS 汇编语言,也可能是 Intel x86 汇编语言。 总之,由于汇编语言是包含了特定处理器特性(如指令集、操作数寻址、寄存器数量和种类、寄存器存储的数值)的低级语言,因此存在着多种汇编语言。即使是同一 CPU,也可以采用不同的汇编语法并与之对应的汇编器,翻译成机器语言;
汇编语言这一特性程序员造成的影响是显然的:当编程工作从一种处理器迁移到另一种处理器时,汇编语言程序员必须学习新的语言。不利的一面是,指令集、操作数类型、寄存器在不同的汇编语言中通常是不同的;有利的一面是,大多数汇编语言倾向于遵从相同的基本模式。因此,一旦程序员学会了一种汇编语言,就能够迅速学会其他汇编语言,并且通常是学习新的细节,而不是学习新的编程风格。一个了解了汇编语言基本范式的程序员可以快速学会新的汇编语言。
pep/9 汇编、plan9 汇编、x86 汇编、MIPS 汇编,相当于不同的语言,Go 用的就是 plan9 汇编。
1.7 汇编与反汇编
汇编语言和机器语言基本上是一一对应的,将汇编语言编写的程序转化成机器语言的过程称为汇编;反之,机器语言程序转化成汇编语言程序的过程则称为反汇编。这一点和高级编程语言有很大不同,因此懂得汇编必然就懂得 CPU 指令集和内存的微体系架构。
反汇编工具有 objdump、otool,与 objdump -Sl 能力接近的命令是 otool -tV,表示列出指令段。
对于 Go 自己提供了汇编与反汇编工具,
go tool objdump <binary>相当于objdump <binary>、otool -t <binary>,不过输出格式都不一样;go tool compile -S <gofile>是没有连接的汇编结果,地址可能会跟反汇编结果不太一样;- Go 汇编和前两者其实是不同的,Go 汇编其实算是 Go 源代码,和前面两种格式也不尽相同。
1.8 函数与过程
- 术语“过程”或“子程序”指代一段可以被调用、执行计算并将控制权归还调用者的代码。术语“过程调用”或“子程序调用”指代了这样的调用过程。过程可以有参数。
- 术语“函数”指代返回以单一值为结果的过程,与过程类似,函数可以有参数。
所以说函数的概念隶属于过程。
2 微体系架构
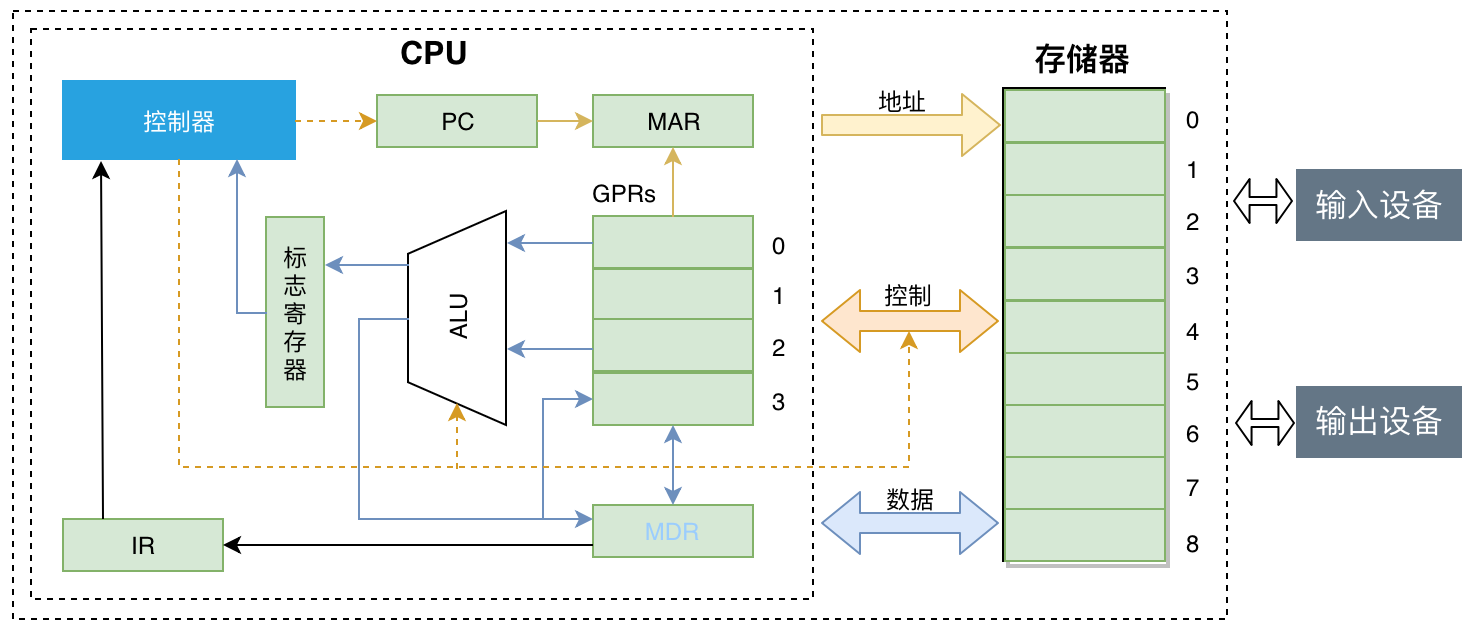
2.1 内存
首先有必要了解一下随机存取存储器(RAM) ,顾名思义,RAM 是针对随机(而不是顺序)访问进行优化的,可以直接认为随机访问过程是直接命中的;此外,RAM 提供读写功能,一般写入时间比读取时间要长得多,这需要选择合适的内存技术;最后 RAM 是易失性的,在计算机断电后,值不会持续存在。内存结构,有以下四种引脚
- VCC、GND:电源
- A0-A9:地址信号,决定多少个地址编号,现在一般都是64位了
- D0-D7:数据信号,决定一次可读取的数据,一直以来都是8位
- RD、WR:控制信号
- 64位内存可以存储 2^64 个 1 字节的数据,所以最大容量为 2^64B
- 多于 1 字节的数据就要区分大小端了
- 寄存器的大小才是决定了数据是否要编写分割处理程序,比如寄存器是 64 位的,则大于8个字节的数据运算才需要编写分割处理程序
- 64 位一个指针就是 8 字节
2.2 寄存器
CPU 我们只认识寄存器就可以,其它的对编程来说相对透明:
- 一般叫法(不同CPU架构叫法可能不同):程序计数器、累加寄存器、标志寄存器、指令寄存器和栈寄存器都只有一个,其它的一般有多个(基址寄存器、变址寄存器、通用寄存器都不止一个)
- 8088 有8个通用寄存器(适用于存储任意数据),x86也有8个,32位都在前面加了e(extended),如果仅利用32位寄存器的低16位,此时只需把要指定的寄存器名开头的字母e去掉即可(但是plan9都寄存器不加前缀),amd64前面都加了R
- IR 指令寄存器是 CPU 内部使用,程序员无法通过程序对寄存器进行读写操作。
3 ISA 指令集
ISA 也正是介于软硬件的交界处,是高级语言和操作系统操作的抽象硬件(对硬件的抽象)。
这里自行去查找不同的架构指令集即可(cat /proc/cpuinfo | grep flags | head -1) macOS 可以用 sysctl -a | grep machdep.cpu
4 汇编
4.1 汇编基本范式
前面我们讲了,学汇编语言要学其基本范式,这部分建议学习《计算机体系结构精髓》,它是站在专业程序开发人员的角度进行讲解的。
-
汇编语句一般格式: label: opcode operand1, operand2, …
-
操作数顺序,不同汇编,操作数顺序经常是不一样的
-
寄存器名称,由于寄存器是汇编语言编程的基础,每种汇编语言都提供了标识寄存器的方法。在一些语言中,专门的名字被保留;在另一些语言中,程序员可以为寄存器分配名字。以字母 r 开头并在其后跟随一至两位数字的名字会被保留,用于指代寄存器。有些语言 $10 指代寄存器 10;其他的汇编器则更灵活:允许程序员指定寄存器的名字。
listhd register 6 # 保存列表的起始地址 listptr register 7 # 在列表中移动 -
操作数类型,汇编语言需要为处理器支持的每种操作数类型提供的语法形式,包括寄存器引用、立即数(即一个常数),以及对内存的间接引用
mov r2,r1 # 将寄存器1的内容复制到寄存器2 mov r2,(r1) # 将寄存器1的内容变作指针,指向一个内存,然后将该位置处的值拷贝到寄存器2。(todo)好像有些汇编用到方括号,具体作用有待查证。 movl eax, ebp+8 # 有些汇编在 mov 后加 b、w、l、q 分别表示 1、2、4、8 个字节 mov eax, dword ptr [ebp+8] # 有些汇编用 dword 等表示长度 -
实现带参数的过程调用或函数调用
- 处理器使用内存中的栈保存参数,如 x86 Plan9 汇编
- 处理器使用寄存器传递参数,如 x86 C 汇编,前 6 个参数保存在寄存器,第7个开始保存在栈中
- 处理器使用专用的参数寄存器
-
变量和存储,一些汇编语言使用伪指令 .word 声明 16位存储空间,.long声明32位存储空间
4.2 调用规约
程序寄存器组是唯一能被所有函数共享的资源。虽然某一时刻只有一个函数在执行,但需保证当某个函数调用其他函数时,被调函数不会修改或覆盖主调函数稍后会使用到的寄存器值。因此,IA32采用一套统一的寄存器使用约定,所有函数(包括库函数)调用都必须遵守该约定。主要是要知道哪些寄存器是需要 caller-save,哪些是 callee-save,在编写汇编程序时应注意遵守惯例。
根据惯例:
- 寄存器 %eax、%edx 和 %ecx 为主调函数保存寄存器(caller-saved registers),当函数调用时,若主调函数希望保持这些寄存器的值,则必须在调用前显式地将其保存在栈中;被调函数可以覆盖这些寄存器,而不会破坏主调函数所需的数据。
- 寄存器 %ebx、%esi 和 %edi 为被调函数保存寄存器(callee-saved registers),即被调函数在覆盖这些寄存器的值时,必须先将寄存器原值压入栈中保存起来,并在函数返回前从栈中恢复其原值,因为主调函数可能也在使用这些寄存器。此外,被调函数必须保持寄存器 %ebp 和 %esp,并在函数返回后将其恢复到调用前的值,亦即必须恢复主调函数的栈帧。
plan9 调用规约可以参见参考资料[6]。
4.3 不同汇编的差异
程序员经常要在不同的汇编语言中切换调试,所以了解常见汇编语言的差异是很有必要的。不过这部分我也无法体系的讲,也找不比较全面的资料,只能凭经验列举一些差异,以后遇到不会感到迷惑。
-
操作数顺序问题,plan9 的汇编的操作数的方向是和 intel 汇编相反的,与 AT&T 类似,不过凡事总有例外,如果想了解这种意外,可以参见参考资料[1]。
MOVQ $0x10, AX ===== mov rax, 0x10 | |------------| | |------------------------| -
下面是通用通用寄存器的名字在 IA64 和 plan9 中的对应关系:
| IA64 | RAX | RBX | RCX | RDX | RDI | RSI | RBP | RSP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | RIP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Plan9 | AX | BX | CX | DX | DI | SI | BP | SP | R8 | R9 | R10 | R11 | R12 | R13 | R14 | PC |
-
intel 或 AT&T 汇编提供了 push 和 pop 指令族,plan9 中没有 push 和 pop,栈的调整是通过对硬件 SP 寄存器进行运算来实现的,例如:
subq $0x18, SP // 对 SP 做减法,为函数分配函数栈帧 ... // 省略无用代码 addq $0x18, SP // 对 SP 做加法,清除函数栈帧4.4 C 语言实例
本次测试基于darwin系统(macOS),amd64架构(intel i5),测试 C 程序如下:
int AddNum(int a, int b)
{
return a + b;
}
int main()
{
int c;
c = AddNum(123, 456);
return 0;
}
内存指令或数据是分段的,比如: _TEXT:指令的段定义 _DATA:是被初始化(有初始值)的数据段定义 _BSS:尚未初始化的数据的段定义
我们主要关注指令段,即 _TEXT,对编译或者反汇编来说差异是不大的,实例分析我们就以编译结果进行分析。
- 编译结果如下:
adadeMacBook-Pro:debug ada$ cat main.s
.section __TEXT,__text,regular,pure_instructions
.build_version macos, 10, 14 sdk_version 10, 14
.globl _AddNum ## -- Begin function AddNum
.p2align 4, 0x90
_AddNum: ## @AddNum
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -4(%rbp), %esi
addl -8(%rbp), %esi
movl %esi, %eax
popq %rbp
retq
.cfi_endproc
## -- End function
.globl _main ## -- Begin function main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
subq $16, %rsp
movl $0, -4(%rbp)
movl $123, %edi
movl $456, %esi ## imm = 0x1C8
callq _AddNum
xorl %esi, %esi
movl %eax, -8(%rbp)
movl %esi, %eax
addq $16, %rsp
popq %rbp
retq
.cfi_endproc
## -- End function
- 反汇编结果如下:
adadeMacBook-Pro:debug ada$ otool -tV a.out
a.out:
(__TEXT,__text) section
_AddNum:
0000000100000f60 pushq %rbp
0000000100000f61 movq %rsp, %rbp
0000000100000f64 movl %edi, -0x4(%rbp)
0000000100000f67 movl %esi, -0x8(%rbp)
0000000100000f6a movl -0x4(%rbp), %esi
0000000100000f6d addl -0x8(%rbp), %esi
0000000100000f70 movl %esi, %eax
0000000100000f72 popq %rbp
0000000100000f73 retq
0000000100000f74 nopw %cs:(%rax,%rax)
0000000100000f7e nop
_main:
0000000100000f80 pushq %rbp
0000000100000f81 movq %rsp, %rbp
0000000100000f84 subq $0x10, %rsp
0000000100000f88 movl $0x0, -0x4(%rbp)
0000000100000f8f movl $0x7b, %edi
0000000100000f94 movl $0x1c8, %esi
0000000100000f99 callq _AddNum
0000000100000f9e xorl %esi, %esi
0000000100000fa0 movl %eax, -0x8(%rbp)
0000000100000fa3 movl %esi, %eax
0000000100000fa5 addq $0x10, %rsp
0000000100000fa9 popq %rbp
0000000100000faa retq
4.5 实例分析
我们对编译结果进行简化,以便于我们分析。在 amd64 中,C 语言中 int 是 4 位,在 Go 中 int 是 8 位。
_AddNum: #(编号2)
pushq %rbp #(编号3)
movq %rsp, %rbp #(编号4)
movl %edi, -4(%rbp) # 在 5d0 之后把 123 压入栈
movl %esi, -8(%rbp) # 继续把 456 压入栈
movl -4(%rbp), %esi
addl -8(%rbp), %esi
movl %esi, %eax
popq %rbp # (编号5)
retq
## -- End function
_main:
pushq %rbp
movq %rsp, %rbp #(编号0)
subq $16, %rsp #(编号1)
movl $0, -4(%rbp)
movl $123, %edi
movl $456, %esi
callq _AddNum #(编号6)
xorl %esi, %esi
movl %eax, -8(%rbp)
movl %esi, %eax
addq $16, %rsp #(编号7)
popq %rbp
retq
## -- End function
接下来附上一张内存图及 rsp 和 rbp 的指针,图片的编号对应代码标识的编号,图中编号所在列表示编号中的代码执行后的状态。调试工具的使用请参见本文下一小节的介绍。

C 语言函数规约一般开头和结尾是固定的,那为什么要把 rbp 压入栈临时保存,并用 rbp 来代替 rsp 进行偏移呢?主要是 rsp 受 push、pop、subq、addq 等的影响,所以一般都用 rbp 来进行偏移。
_main
pushq %rbp ;将 rbp 寄存器的值存入栈中
movq %rsp, %rbp ;将 rsp 寄存器的值存入 rbp 寄存器
... ;函数操作
popq %rbp ;读出栈中的数值存入 rbp 寄存器
retq ;结束 main 函数,返回到调用源,返回 rbp 指令处
## -- End function
系统调用就是按规定把该系统调用的数据存放到寄存器,然后执行系统调用就会去读取依赖的寄存器进行调用。 注意上面函数操作处,最后一定要进行栈清理处理,即把 esp 指回 ebp 那个单元,以便下一步 pop ebp 比如函数操作如下:
subq $16, %rsp ;这里分配 16 个字节的内存
... ;加法操作
addq $16, %rsp ;这里就是把 rsp 指回 push 数据之前(没用的数据并不会清空),也就是指向存放 rbp 的那个单元
4.6 lldb 调试汇编代码
最方便的是直接在 xcode 里调试,选中菜单 Debug/Debug Workflow/Always Show Disassembly,在 C 源码中设置断点。调试的时候要注意,像 step over 其实有三个可选项step over/step over instruction(hold Control)/step over thread(hold Control-Shift),最好还是直接在 lldb 命令提示符中执行调试指令。对汇编的单步执行,要用 step over instruction 而非高级语言的 step over。下面列举一些常用的调试指令及其简写。
step over instruction/ni step into instruction/si register read/reg read thread list thread backtrace x/16xb 0x00007ffeefbff5f0-16 显示16个单元,每个单元占1个内存单元(g,1*8=8位),以16进制(x)显示,可以进行加减操作
参考文献
[1] Go assembly language complementary reference. https://quasilyte.dev/blog/post/go-asm-complementary-reference/#external-resources
[2] 矢泽久雄(日). 程序是怎样跑起来的. 版次:2015年4月第1版
[3] J.Stanley Warford. 计算机系统 核心概念及软硬件实现. 版次:2019年1月第1版
[4] 南京大学 袁春风教授. 计算机系统基础(一):程序的表示、转换与链接 https://www.icourse163.org/learn/NJU-1001625001?tid=1206622249#/learn/content?type=detail&id=1211390547&cid=1214042236&replay=true
[5] 汇编 is so easy. https://github.com/cch123/asmshare/blob/master/layout.md
[6] 调用规约. https://github.com/cch123/llp-trans/blob/master/part3/translation-details/function-calling-sequence/calling-convention.md
[7] Douglas Comer(美). 计算机体系结构精髓. 版次:2019年6月第1版